【斯坦福最新 AI 研究报告出炉:中美AI模型质量差距缩小至0.3%】4 月 8 日,nature 发文,斯坦福大学以人为本人工智能研究所发布的《2025 年人工智能指数报告》显示,人工智能领域的竞争日益激烈:中国高性能 AI 模型的数量和质量不断提升,对美国的领先地位构成挑战,顶级模型之间的性能差距正在缩小。
美国此前在模型质量方面的领先优势已经消失。中国是人工智能出版物和专利产出最多的国家,如今其开发的模型在性能上已经与美国的竞争对手不相上下。2023 年,在大规模多任务语言理解测试(MMLU)中,中国领先的模型落后于美国顶级模型近 20 个百分点。然而,到 2024 年底,美国的领先优势缩小到了 0.3 个百分点。
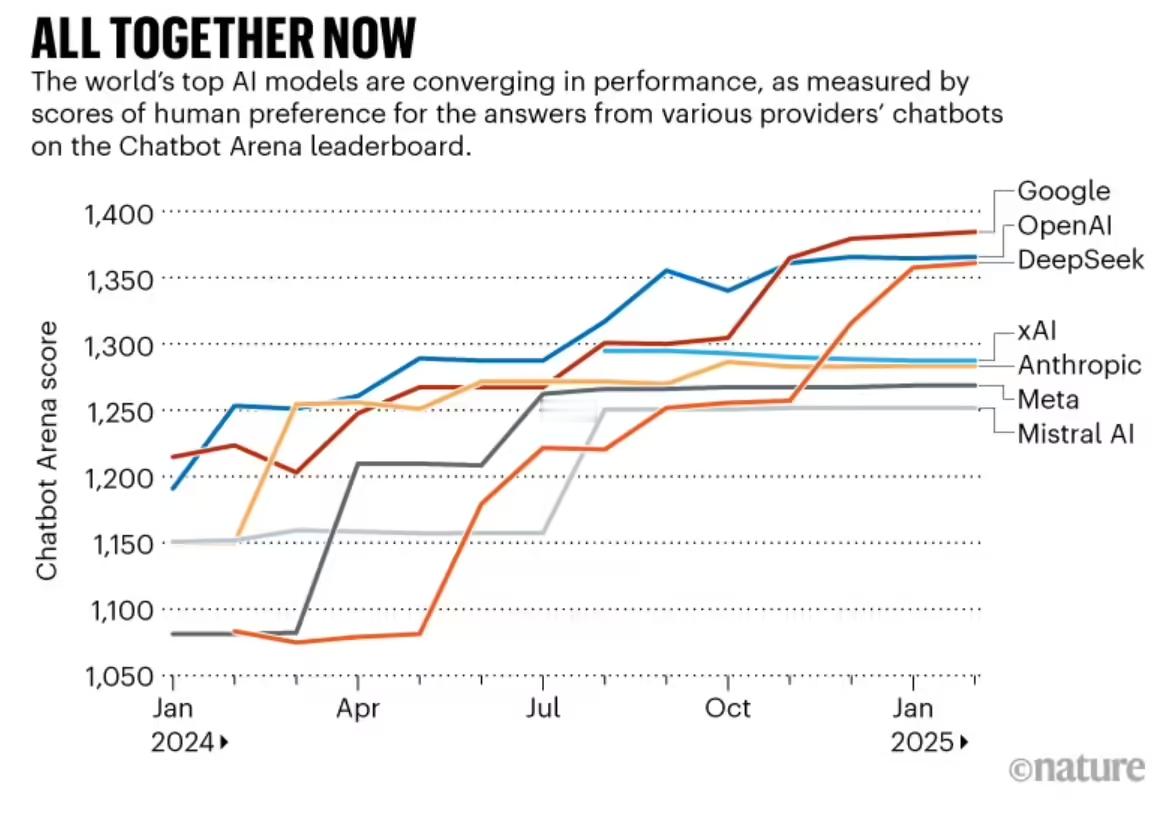
世界各顶级 AI 模型之间性能已无太大差距
该报告强调,随着人工智能的快速持续发展,没有一家公司能够脱颖而出。在聊天机器人竞技场排行榜上,2024 年初排名第一的模型比排名第十的模型得分高出约 12%,但到 2025 年初,这一差距缩小到了 5%。报告称:“前沿领域的竞争越来越激烈,也越来越拥挤。”
该指数显示,通过使用更多决策变量、更强的计算能力和更大的训练数据集,生成式人工智能模型平均而言仍在变得更“大”。但开发人员也在证明,更小、更精简的模型也能有出色的表现。由于算法的改进,如今的模型性能与两年前规模大 100 倍的模型性能齐平。该指数称:“2024 年是小型人工智能模型的突破之年。”
纽约伊萨卡康奈尔大学的计算机科学家巴特・塞尔曼表示,很高兴看到像中国的 DeepSeek 这样相对小型、低成本的研究成果证明了自己的竞争力。他说:“我预计我们会看到一些由五人甚至两人组成的独立团队,他们会提出一些新的算法想法,从而改变现状。这很好。我们不希望世界只由一些大公司掌控。”
报告显示,如今绝大多数强大的人工智能模型是由工业界而非学术界开发的:这与 21 世纪初神经网络和生成式人工智能尚未兴起情况正好相反。报告称,2006 年之前,工业界开发的著名人工智能模型不到 20%,2023 年这一比例为 60%,2024 年则接近 90%。
美国仍然是强大模型的最大生产国,2024 年发布了 40 个模型,中国发布了 15 个,欧洲发布了 3 个。但许多其他地区也在加入这场竞赛,包括中东、拉丁美洲和东南亚。
塞尔曼说:“2015 年左右,中国走上了成为人工智能领域顶尖参与者的道路,他们通过教育投资实现了这一目标。我们看到这开始有了回报。”
AI 领域还出现了“开放权重”模型在数量和性能上的惊人增长,如 DeepSeek 和 Meta 的 LLaMa。用户可以自由查看这些模型在训练过程中学习到的并用于预测的参数,不过其他细节,如训练代码,可能仍保密。最初,不公开这些因素的封闭系统明显更优越,但到 2024 年初,这些类别中顶级竞争者之间的性能差距缩小到了 8%,到 2025 年初则缩小到了 1.7%。
加利福尼亚州门洛帕克的非营利性研究机构 SRI 的计算机科学家、该报告的联合主任雷・佩罗特说:“这对任何无力从头构建模型的人来说肯定是好事,包括许多小公司和学者。”OpenAI 计划在未来几个月内发布一个开放权重模型。
2022 年 ChatGPT 公开推出后,开发人员将大部分精力投入到通过扩大模型规模来提升系统性能上。该指数报告称,这一趋势仍在继续:训练一个典型的领先人工智能模型所消耗的能源目前每年翻一番;每个模型使用的计算资源每五个月翻一番;训练数据集的规模每八个月翻一番。
然而,各公司也在发布性能非常出色的小型模型。例如,2022 年在 MMLU 上得分超过 60% 的最小模型使用了 5400 亿个参数;到 2024 年,一个模型仅用 38 亿个参数就达到了相同的分数。小型模型比大型模型训练速度更快、回答问题更迅速,且能耗更低。佩罗特说:“这对各方面都有帮助。”
塞尔曼说,一些小型模型可以模仿大型模型的行为,或者利用比旧系统更好的算法和硬件。该指数报告称,人工智能系统使用的硬件的平均能源效率每年提高约 40%。由于这些进步,在 MMLU 上得分超过 60% 的成本大幅下降,从 2022 年 11 月的每百万个 token 约 20 美元降至 2024 年 10 月的每百万个 token 约 7 美分。
尽管在几项常见的基准测试中取得了显著进步,但该指数强调,生成式人工智能仍然存在一些问题,如隐性偏见和“幻觉”倾向,即吐出虚假信息。塞尔曼说:“它们在很多方面给我留下了深刻印象,但在其他方面也让我感到恐惧。它们在犯一些非常基本的错误方面让我感到惊讶。”(凤凰科技)










申
那些个国内的专家出来走两步
签字笔
有暴降280倍的说法?!
hand
美国人还在那里自我感觉良好?
阿栗
老美还自嗨,成本是你家五十分之一,推理水平差不多,你管这叫平分秋色?明显中国算法领先,老美靠芯片无脑堆叠算力而已,在老美那边花钱解决而不是靠技术算法
喝芝士奶茶
deepseek伟大[点赞]
你的头圆吗
偷瞄了deepseek吧,就持平,扯平了。因为你们那个效率低,成本高,能耗高不先进。还要收费,诈取额外钱财。
君云孟
抬高美国,贬低中国,一般公式,套路!
太原
0.3%这就是自己给自己找台阶下
李瞿熙
许多公知不是说差代吗?
阿婷儿??
米国人好面子,明明被DS甩到四千八千里外,却要说自己差一点被追上。
二狗是GAY
阿里,ds,豆包,还有鹅厂,看最后谁能胜出吧