今晚听理想的Ai Talk一个比较印象深的点是:超级对齐。
超级对齐的目的是,提升模型的下限,从而提高辅助驾驶的安全性,不让Ai胡来,符合法规常识,和司机驾驶行为一致。
训练方式是基于人类反馈的强化学习(RLHF),看人类是否接管作为反馈,进行强化学习。
李想介绍了学习的三个维度:舒适性(G值)、安全性(碰撞)、逻辑选择(比如变道)尽量和人类行为保持对齐。
理想汽车[超话]理想ai talk第二季
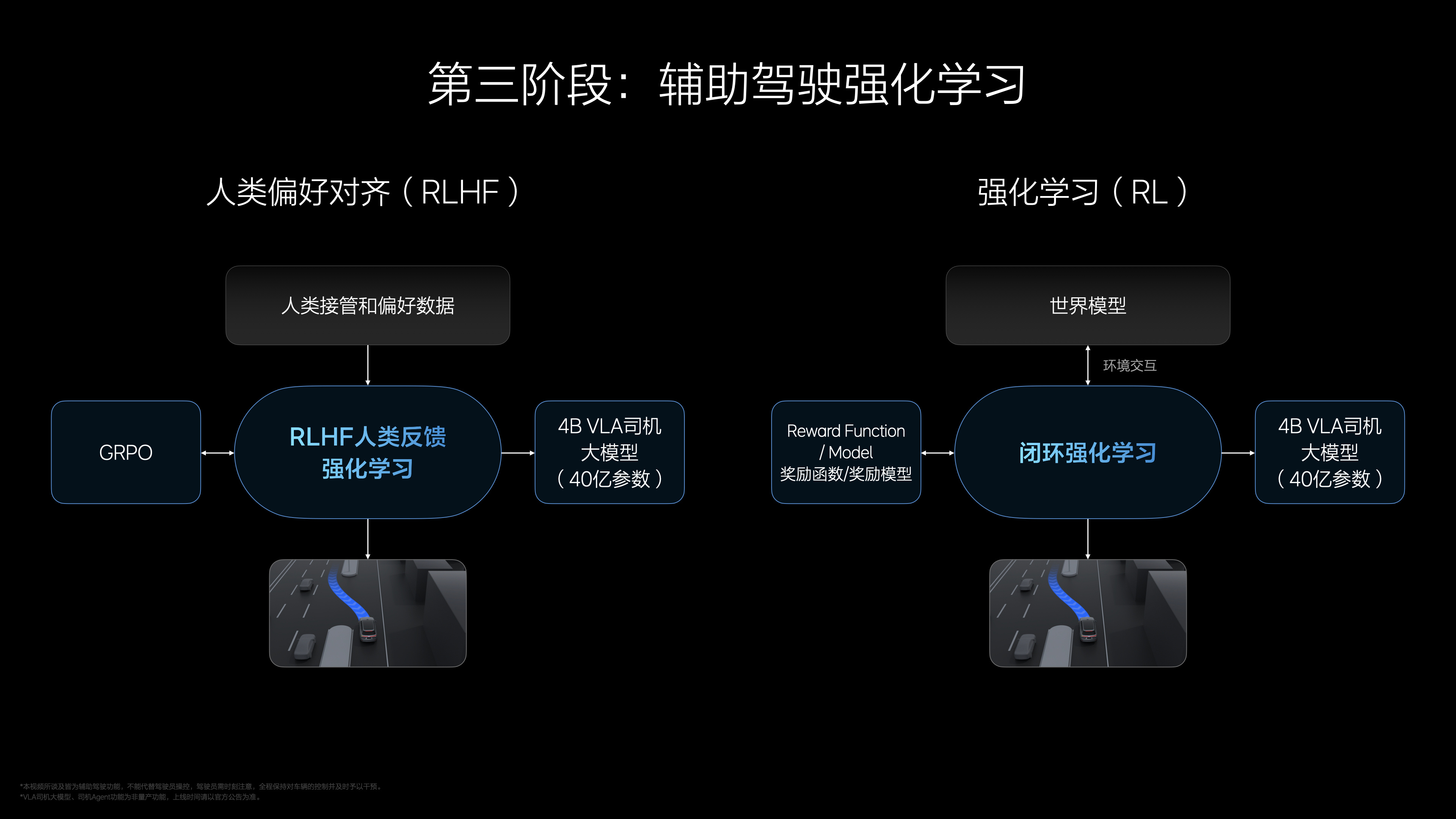
今晚听理想的Ai Talk一个比较印象深的点是:超级对齐。
超级对齐的目的是,提升模型的下限,从而提高辅助驾驶的安全性,不让Ai胡来,符合法规常识,和司机驾驶行为一致。
训练方式是基于人类反馈的强化学习(RLHF),看人类是否接管作为反馈,进行强化学习。
李想介绍了学习的三个维度:舒适性(G值)、安全性(碰撞)、逻辑选择(比如变道)尽量和人类行为保持对齐。
理想汽车[超话]理想ai talk第二季

作者最新文章
热门分类
汽车TOP
汽车最新文章