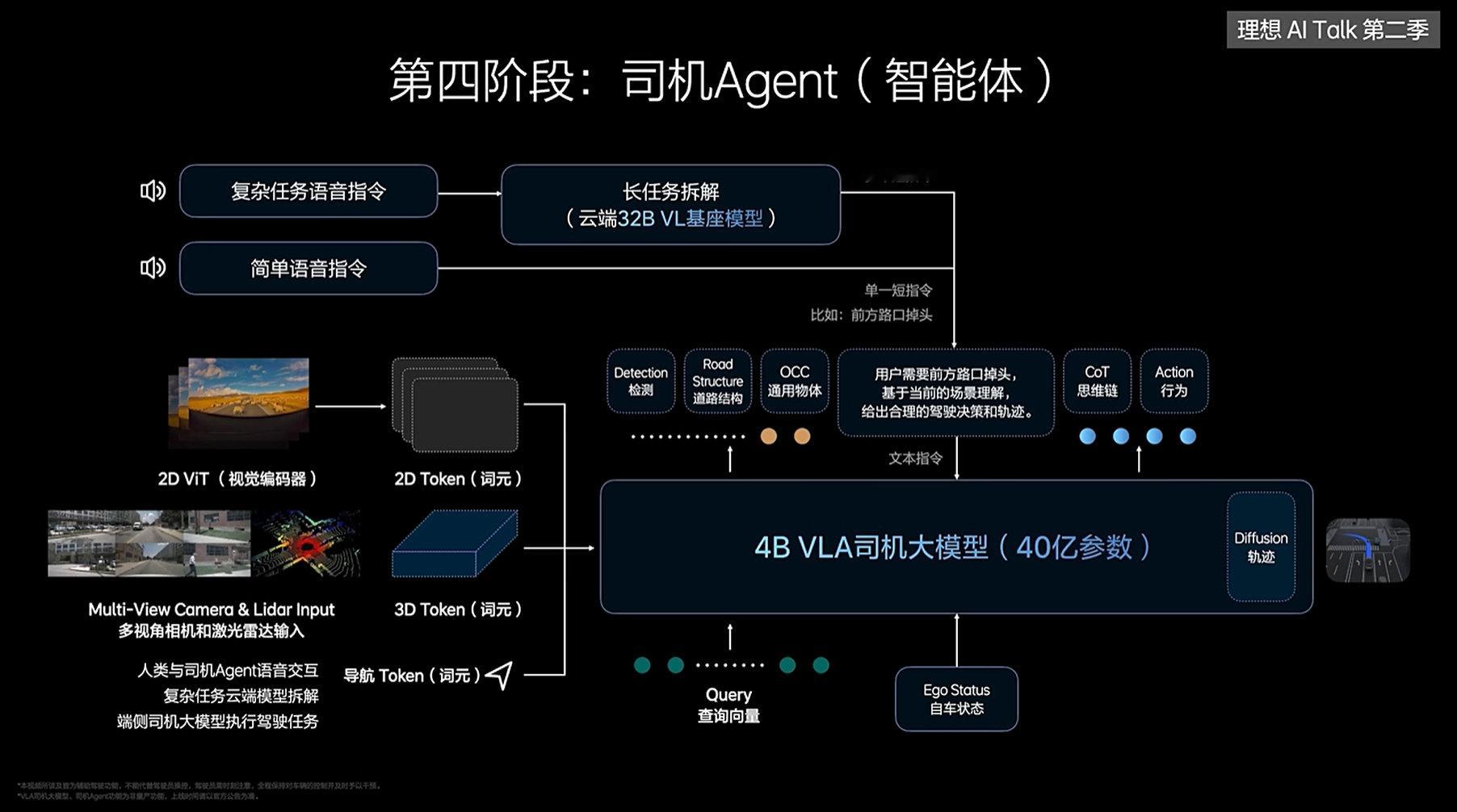
李想认为VLA(司机大模型),它会像人类一样,用3D的vision(视觉)和2D的组合,去看整个真实的物理世界,能够去看懂导航软件如何运行,而不是像VLM(视觉语言模型)那样只能看到一张图片。另外,它有自己的整个脑系统,不但要看到物理世界,还能够理解这个物理世界。它有它的language(语言),然后它也有它的CoT(思维链),有推理的能力。并且能够像人类一样去执行和做出反应。
为了让用户和VLA(司机大模型)能够用正常的语言沟通,理想搭建了一个司机的Agent(智能体),如果是一些通用的短指令VLA(司机大模型)直接就处理了,不需要再经过云端。如果是一些复杂的指令,先要到云端的32B那里,VL(视觉和语言)处理完以后,(因为它理解交通的一切) ,再交给VLA(司机大模型)来进行处理。
可以看出这里最关键的是智能体,它让VLA和人能够正常沟通,你可以把智能体当做一个有思维的人并且和你同频。
以上就是理想最终交付给用户的产品,一个能够像人类司机一样去理解物理世界,能够像人类司机一样去开车,去处理复杂的问题,也能像人类司机一样跟其他人类进行沟通的辅助驾驶方案!理想AI Talk第二季李想谈辅助驾驶到了新十字路口李想说当前竞争环境下要练基本功