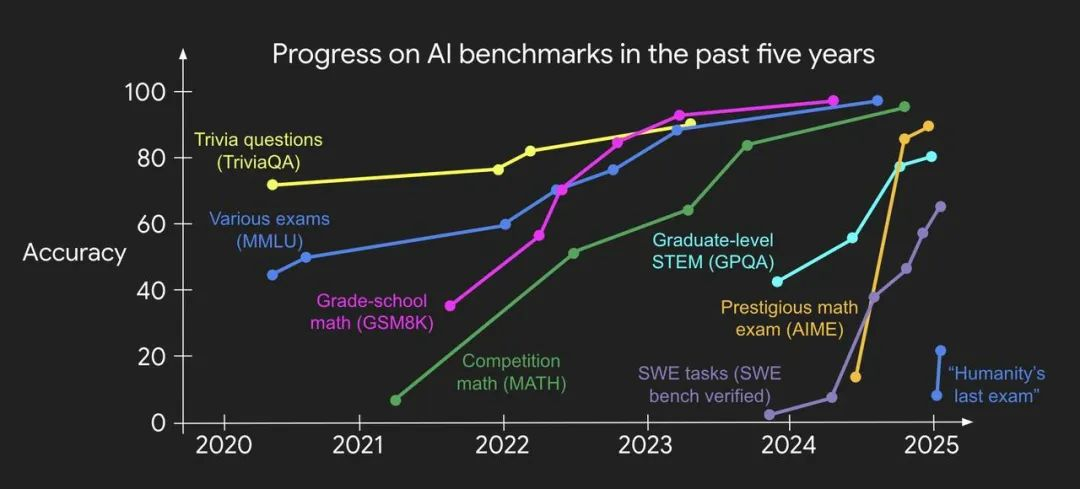
红杉中国最近推出了AI基准测试工具xbench,简单来说就是你们发AI 模型,我来测各AI 模型的真实水平。
我觉得辅助驾驶也非常需要这样的benchmark(基准测试)工具。
不过事实就是难度很大。主要是两个难度,首先要创造AI 模型难,要给AI 模型出考卷来测试他们更难。其次,因为技术太过于日新月异,评估的有效时间会急剧缩短,需要长期维护。
红杉测评的三个维度或许可以参考:
——理论维度:评估AI系统的能力上限与技术边界
——落地价值:量化AI系统在真实场景的效用价值(utility value),需要动态对齐现实世界的应用需求,基于实际工作流程和具体社会角色,为各垂直领域构建具有明确业务价值的测评标准
——长青评估机制:通过持续维护并动态更新测试内容,以确保时效性和相关性。