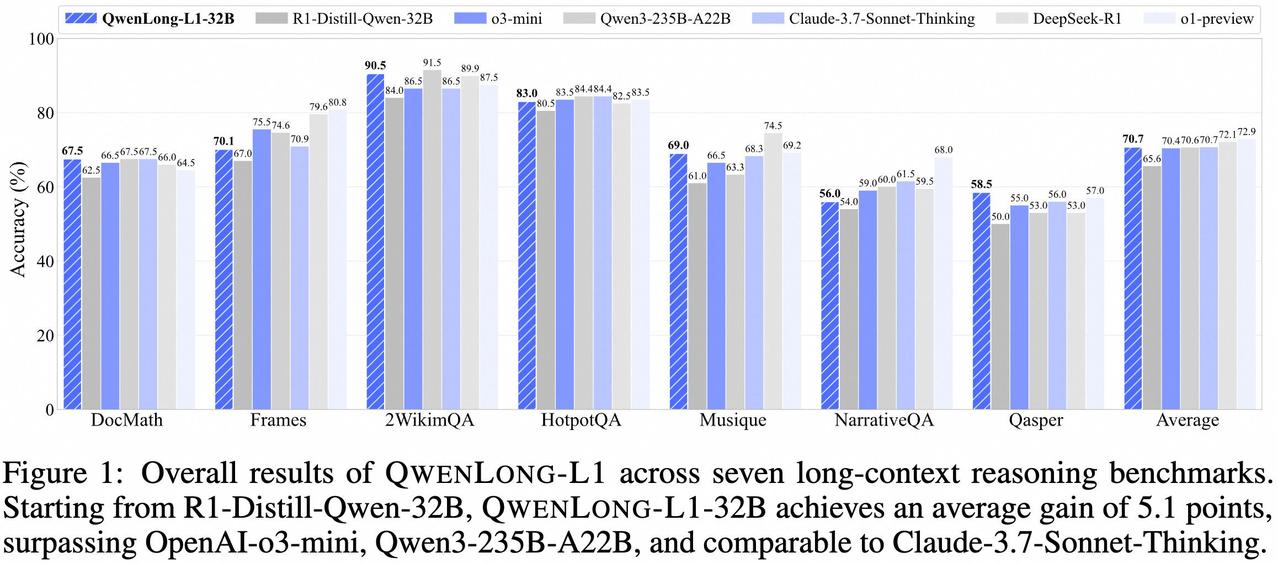
阿里刚刚放出了:QwenLong-L1-32B,一款用于长上下文推理的LLM,性能优于o3-mini、Qwen3-235B-A22B,与Claude-3.7-Sonnet-Thinking相当 QwenLong-L1-32B经过QwenLong-L1框架训练,是首个通过强化学习训练的长文本情境推理模型,在七个长文本情境文档问答基准测试上表现优秀 QwenLong-L1使用强化学习方法,尤其是GRPO和DAPO算法,结合基于规则和基于模型的混合奖励函数,来提升模型在长上下文推理中的性能 阿里发布了一套解决长文本推理问题的完整方案,包括模型、数据集、训练方法和评估体系 LLM qwen QwenLongL1编程严选网