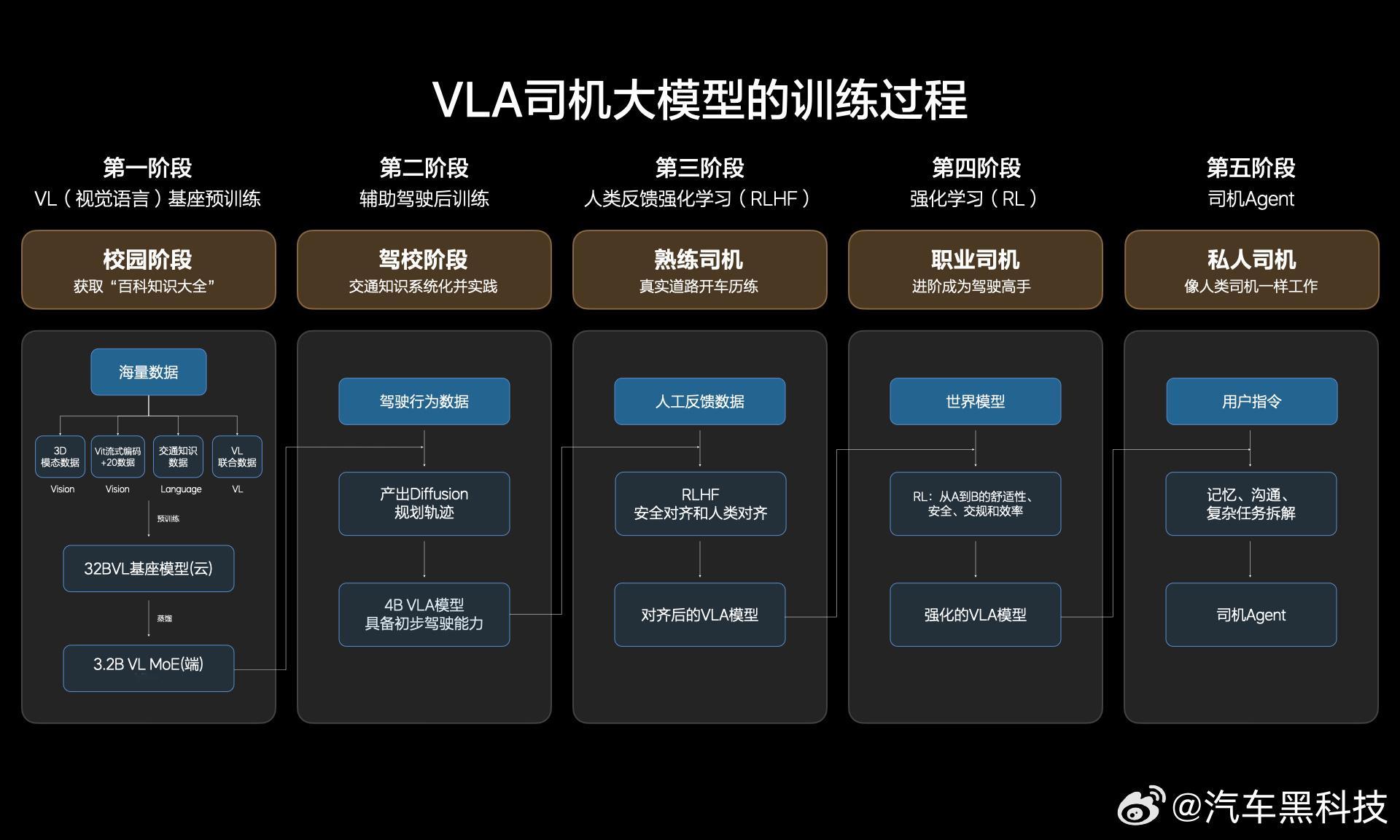
【听不懂的汽车黑话什么是VLA 】小黑简单科普一下,VLA —— Vision-Language-Action,即 视觉-语言-动作 模型,机器通过视觉(看得明白)、语言(听得懂),最后输出动作(打方向盘、踩刹车、机械臂拿起杯子、人形机器人绕过障碍物等)。大白话,就是拥有通用AGI的机器学会世界知识,从而指导机械自己输出动作。
【VLA可直接输出动作指令】
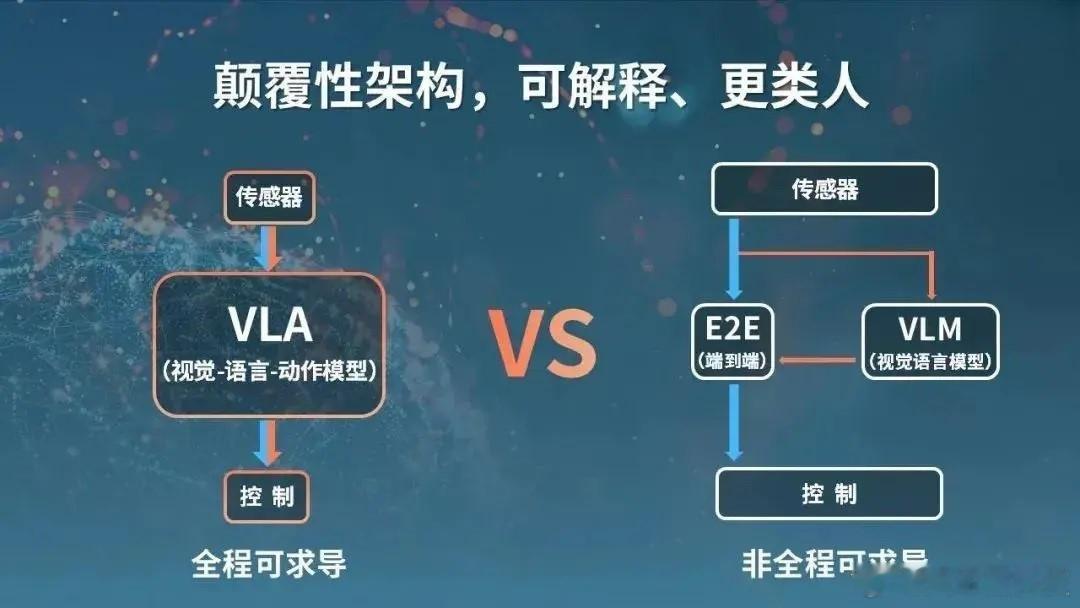
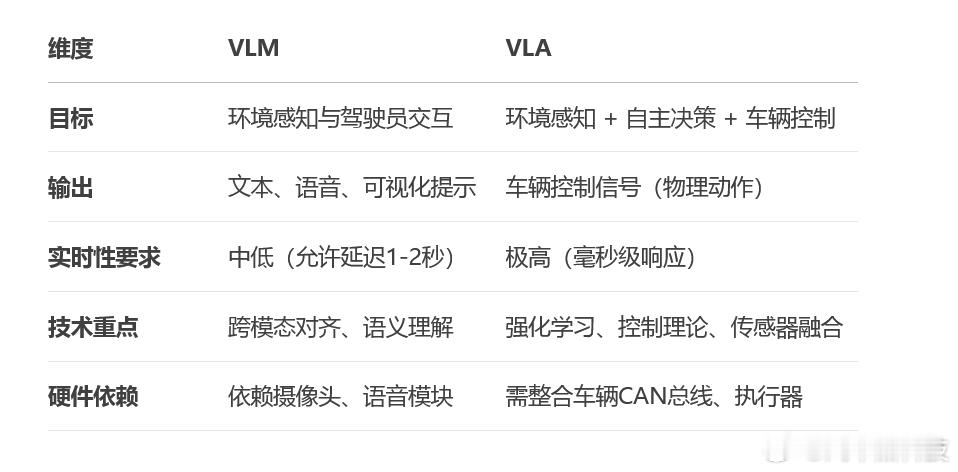
VLA 相比 VLM(Vision-Language Model)视觉语言模型,多出了一个 “A” ,这个 “A” 就是引导机器如何做动作,而后者VLM,只能输出文本、语音反馈、决策建议或可视化提示(如中控屏的警示信息),而不能直接控制车辆、机械。
【VLA场景非常广】
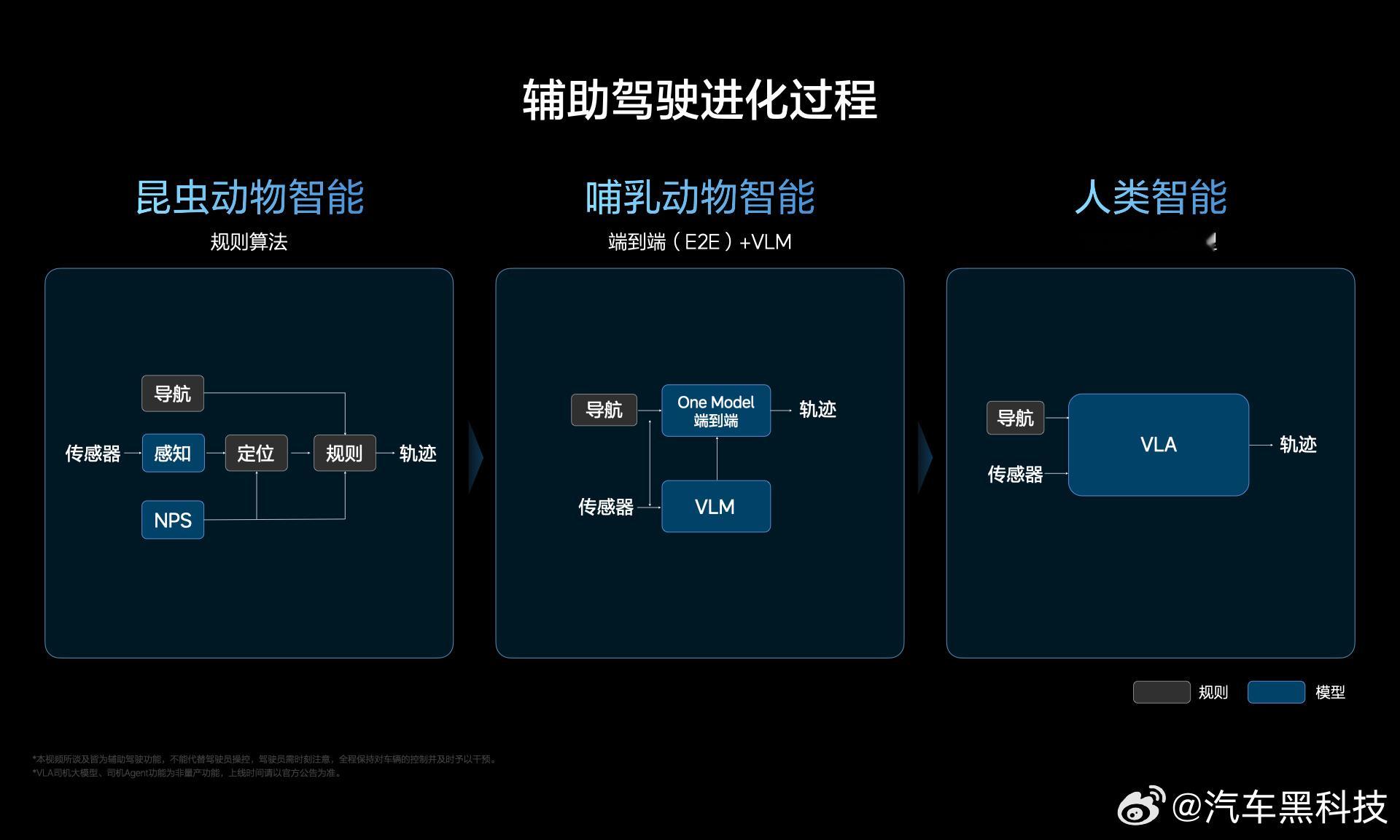
VLA 不仅仅用于汽车的智能辅助驾驶,它本身其实是从机器人、机器臂中发展出来的,所以它是通用的智能解决方案,通过改变使用场景,可以获得不同的 “智能具身” ,如汽车、人形机器人、焊接车间机械臂、甚至扫地机器人等家电。可以简单的理解为VLA就是意识,只不过被安放在不同的机器上,从而变成有意识的机械,协助人类。
【VLA在辅助驾驶中的独特优势】
闭环控制能力:VLA可将视觉感知(如检测到前方障碍物)与语言指令(如“保持安全车距”)结合,直接控制刹车和油门,实现自适应巡航(ACC)。
多模态决策融合:在复杂路口,VLA可同时处理视觉信号(交通灯状态)、语言指令(导航目标)和地图数据,生成转向和速度控制指令。
人机协同增强:比如,驾驶员说“帮我超车”,VLA通过视觉确认安全距离后,自动完成加速和变道。将自然语言指令转化为精准动作,降低驾驶员认知负荷。
持续学习与优化:VLA通过强化学习在仿真环境中训练,优化极端场景(如雨雪天气)下的控制策略。比静态规则的VLM系统更适应长尾场景。
【VLA和VLM并非互斥而是互补】
VLM 负责语义理解和交互(如回答 “为什么刹车?”),提升用户体验。VLA 负责高可靠性控制(如自动变道),确保行驶安全。
通过VLM增强VLA的意图理解能力(如解析模糊指令 “开稳一点”),同时利用VLA的实时反馈优化VLM的环境感知精度。汽车黑科技



![重押VLA,理想汽车端到端模型负责人夏中谱将于近期离职[思考]有知情人士表示,](http://image.uczzd.cn/7319928434237651033.jpg?id=0)





