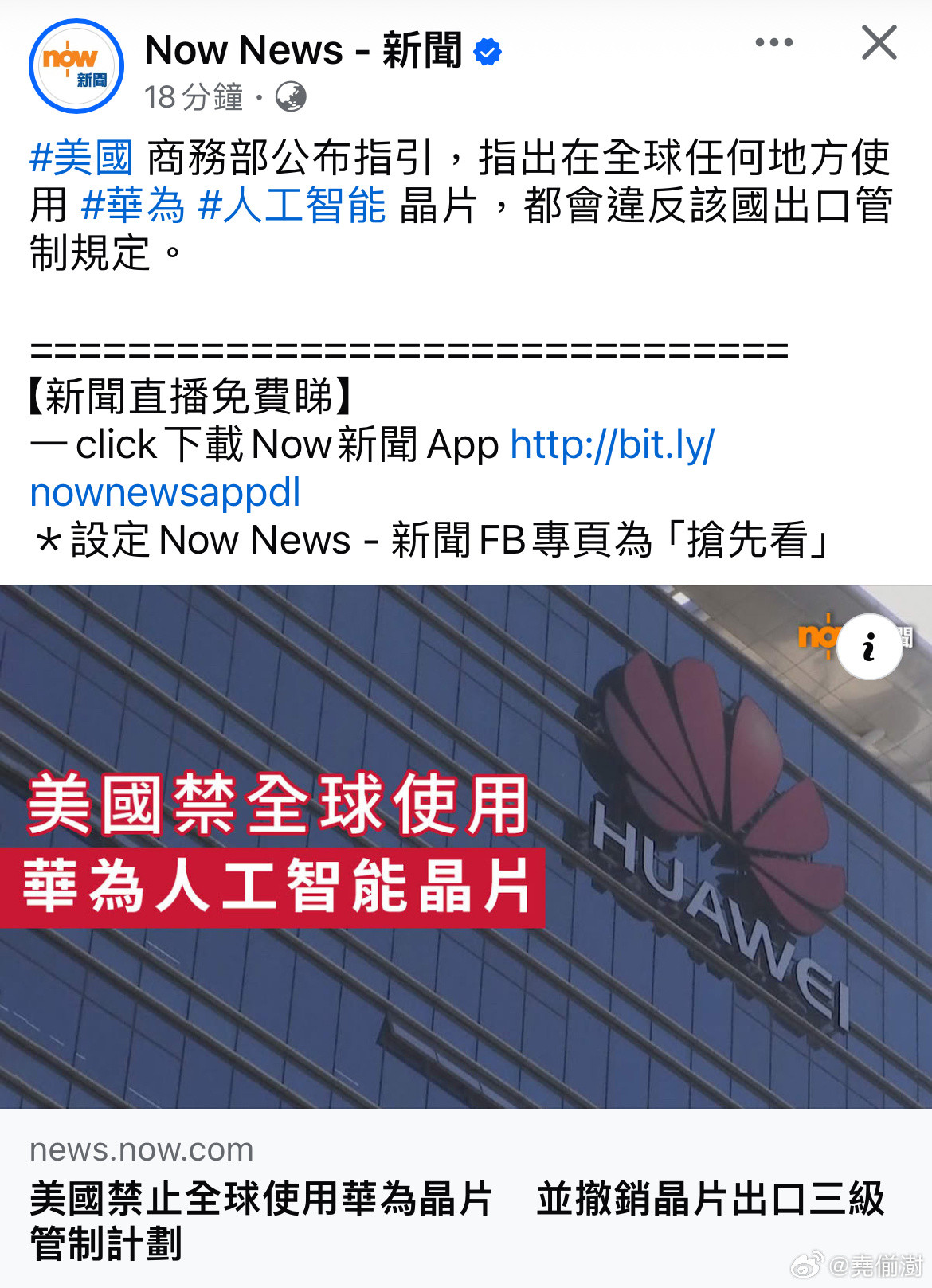
AI多轮对话易变人工智障和AI对话最好一次说清楚
聊着聊着,大模型的智商像跳水一样越来越低?这不是你的错觉!
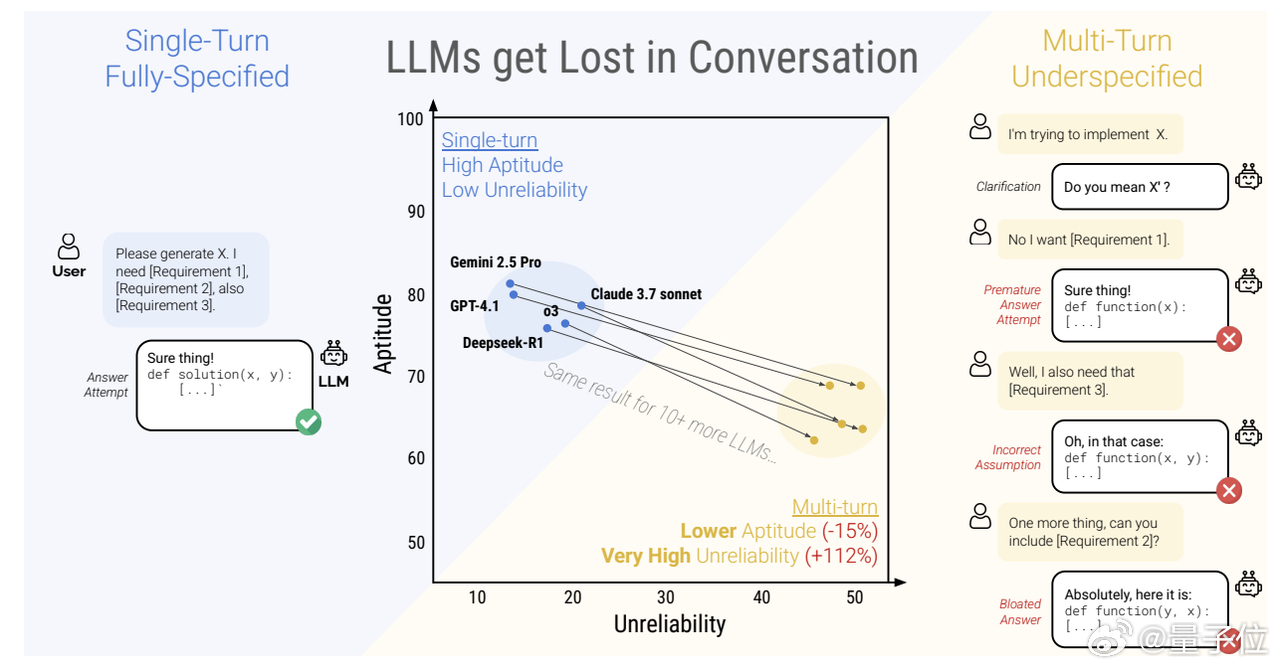
来自微软研究院和Salesforce研究院的最新研究发现,大模型在多轮对话中的表现均显著低于单轮场景。【图2】
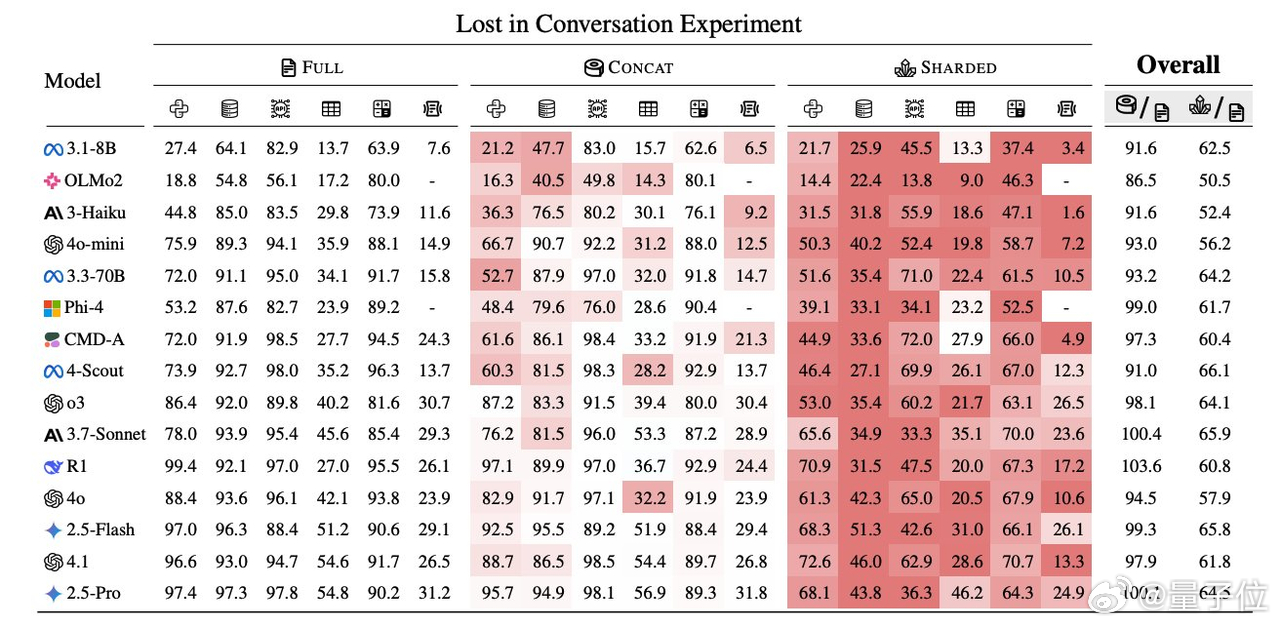
在六大生成任务(代码生成、数学解题、SQL编写、API调用、数据转文本和文档摘要)当中的平均性能下降甚至都能达到39%,即使是SoTA模型也不例外。【图3】
这是咋搞的呢?研究人员发现,这是由于LLMs常在对话早期做出假设,并过早尝试生成最终解决方案,且对此过度依赖。【图4】
再加上需要多轮对话的场景下,用户初始指令往往不完整,需要一步一步澄清。于是当我们意识到大模型在对话中偏离正确方向时,它们已经彻底迷失且无法自我修正。
研究人员将性能下降分解为两个因素:最佳情况下的性能下降和性能的波动范围。通过对20万+模拟对话的分析发现:【图5】
- 多轮对话的最佳情况下,模型的能力出现了15%小幅下降
- 多轮对话中,模型最优与最差回答的差距显著扩大,意味着其表现变得极不稳定。
- 单轮场景表现优异的模型,在多轮对话中与较小模型的不可靠程度相当。
这种性能下降很难通过“对话回顾”和“滚雪球”的策略缓解,降低生成随机性同样收效甚微。【图6】
不过,用户还是可以采用一些简单方法缓解,比如说:
- 尽量将所有需求整合到单次提示中,而非通过多轮对话逐步澄清。
- 当对话偏离正轨时,直接整合摘要开启新会话。
论文原文: